

Open Source Large Language Models: Everything You Need to Know

Explore the world of open source large language models—what they are, key examples, how they work, their benefits and risks, and how developers and businesses can use them.
In recent years, the rise of open source large language models (LLMs) has transformed how organizations, start-ups, researchers and developers approach natural language processing (NLP), generative AI and intelligent applications. Rather than being locked behind proprietary APIs, you can now access, run, fine-tune and adapt powerful LLMs whose weights, code or architectures are publicly available.
In this detailed guide we will cover:
- What we mean by “open source large language models”
- Why they matter for AI development and business
- Key examples of open source LLMs today
- How they work behind the scenes
- Use-cases and adoption strategies
- Advantages and challenges of open source LLMs
- Best practices for selecting, deploying and managing them
- Future trends to watch in open source LLMs
Let’s dive in.
1. What Are Open Source Large Language Models?
1.1 Defining the Term
By “open source large language models” we refer to LLMs which:
- Are built with large numbers of parameters (often billions) and trained on large text corpora.
- Offer access to model weights, or at least an open architecture and training code.
- Are released under freely usable licences (or at least with open or research-friendly access) so developers or researchers can run, fine-tune, adapt or integrate the model.
- Are large enough to perform broad NLP tasks (generation, summarisation, translation, question answering) rather than narrow domain models.
IBM defines open source LLMs as models “licensed for commercial use, trained with open weights and available for fine-tuning”. IBM+2theaisanctuary.org+2
1.2 Why “Large” Matters
The “large” in LLM typically implies high parameter counts (tens to hundreds of billions), large training corpora, and significant compute investment. Many capabilities (emergent reasoning, multilingual generation, complex code generation) only appear at scale. For example, the model BLOOM has 176 billion parameters. Wikipedia+2digitalogy.co+2
1.3 What “Open Source” Means in This Context
“Open source” can vary in meaning: full weights + code + permissive licence is the ideal; some models may have open architectures but restricted use. Regardless, the key idea is that you have significantly more direct control, transparency and ability to adapt than closed-API models.
2. Why Open Source Large Language Models Matter
2.1 Democratizing AI Access
Previously, the highest-performing LLMs were proprietary (e.g., GPT‑4) and accessible only via paid APIs. Open source LLMs allow researchers, startups, academia and smaller organisations to access, inspect, and build upon such capabilities—opening the field to many more actors.
2.2 Customisation and Control
With open source models you can tailor the model to your specific domain, fine-tune on your data, adapt to local languages or niche industry verticals. You reduce reliance on a black-box vendor.
2.3 Cost Efficiency & Deployment Flexibility
Running your own models (on-premise or cloud) can reduce API costs, avoid usage limits, and give you more flexibility in inference. You gain the ability to deploy in private or regulated environments.
2.4 Research and Innovation
Open source LLMs accelerate research in AI safety, interpretability, multilingual AI, model ecosystems and new architectures. For example, the model PolyLM explores multilingual instruction-tuning in open source. arXiv+1
2.5 Competitive Advantage
For businesses, using open source LLMs strategically can enable unique features, data ownership, and faster innovation. Especially relevant for startups with niche needs or lower budgets.
3. Key Examples of Open Source Large Language Models
Here are some of the most significant open source LLMs you should know about:
3.1 BLOOM
A multilingual model developed by the BigScience research initiative. It has 176 billion parameters and supports 46 languages and 13 programming languages. Wikipedia+2theaisanctuary.org+2
3.2 LLaMA / LLaMA 2
From Meta AI, originally released with parameter sizes from 7B to 65B, later versions (LLaMA 2) are popular open-source models with strong community adoption. IT Pro+2DataCamp+2
3.3 GPT‑J
Developed by EleutherAI, GPT-J-6B is a 6 billion-parameter open source model available under the Apache license. Wikipedia+1
3.4 Falcon & Other Emerging Models
Models like Falcon (from TII) and other open source LLMs (MPT-30B, StarCoder) indicate the growing ecosystem. According to IBM’s overview, MPT and others are licensed for commercial use. IBM+1
3.5 h2oGPT
An open source suite by H2O.ai, with model sizes from 7B to 40B parameters under permissive licences. arXiv
These examples show the broad diversity—not just in size, but in focus (multilingual, code, instruction-tuned) and licence/availability.
4. How Open Source Large Language Models Work
4.1 Architecture: Transformer Models
Most open source LLMs use transformer architectures (encoder-decoder or decoder-only) with self-attention mechanisms. They are pre-trained on very large text corpora (internet text, books, code).
4.2 Pre-Training and Fine-Tuning
- Pre-training: model learns general language patterns from massive datasets.
- Fine-tuning / instruction tuning: model is further trained to follow instructions, optimise for downstream tasks (chat, summarisation, QA).
4.3 Parameter Count and Scale
Scale matters for capability. For example, BLOOM at 176B parameters offers stronger multilingual and reasoning capacity compared to smaller models. digitalogy.co+2DataCamp+2
4.4 Token Context Window
Larger context windows allow the model to process longer documents. Some newer open-source models support longer contexts which is good for real-world use-cases.
4.5 Inference & Deployment
Running LLMs requires compute (GPUs/TPUs) or specialised hardware. Many models support quantisation (e.g., 4-bit, 8-bit) to reduce resource needs. Also, you can use cloud or on-premise deployment.
4.6 Licence and Usage Considerations
Open source models come with licences (Apache 2.0, MIT, RAIL) that define how you can use, modify, distribute them. Always check commercial/production restrictions. For example, IBM points out MPT-30B is licensed for commercial use. IBM
5. Use-Cases and Adoption Strategies for Open Source Large Language Models
5.1 Generative Text and Content Creation
From blog writing, marketing copy, report summarisation to code generation—open source LLMs enable rich automation. For example, using GPT-J or BLOOM to generate multilingual content.
5.2 Domain-Specific Fine-Tuning
You can fine-tune open source LLMs on your own data (customer support transcripts, product manuals, legal docs) to create specialised models with excellent performance for your domain.
5.3 Multilingual and Regional Language Models
Open source models like BLOOM support many languages and enable developers in non-English speaking regions to adopt high-capability AI. This is especially important in markets like India.
5.4 Research, Experimentation and Education
Academia and research labs use open source LLMs to experiment with interpretability, safety, alignment, novel architectures—without being locked into proprietary ecosystems.
5.5 On-Premise or Private Deployment
If data privacy, regulatory compliance or offline accessibility matter (e.g., health, finance, government), running your own open source LLM may be beneficial.
5.6 Chatbots, Virtual Assistants & Retrieval-Augmented Generation (RAG)
Open source LLMs can be integrated into chatbots, voice assistants, or RAG systems (where a retrieval system fetches domain relevant data and passes it to the LLM).
5.7 Code Generation and Developer Tools
Some open source LLMs specialise in code generation (e.g., StarCoder). These enable developer productivity tools, automation, and internal use cases.
6. Advantages & Benefits of Open Source Large Language Models

6.1 Transparency & Trust
With open weights and code you can audit the model, understand behaviour, address bias, and customise safety.
6.2 Cost Control
Avoid high‐cost API usage and vendor lock-in. You can deploy and scale as you see fit.
6.3 Customisation and Ownership
Have full control: fine-tune, integrate, adapt to your needs. For businesses this means differentiation.
6.4 Innovation Momentum
The open source community drives fast innovation; new models, libraries, tools and datasets appear frequently. You benefit from community contributions.
6.5 Ethical and Inclusive AI
Open source models support efforts to build inclusive, multilingual, regionally relevant AI rather than only big global players.
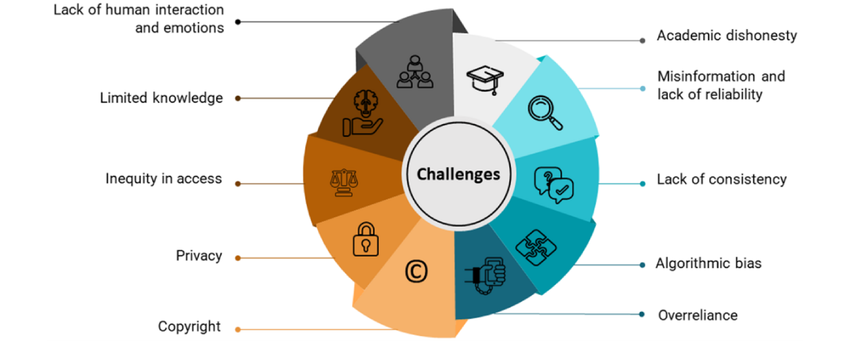
7. Challenges & Risks of Open Source Large Language Models
7.1 Resource Requirements & Infrastructure
Running or fine-tuning large open source LLMs requires substantial compute, memory and infrastructure. Smaller organisations may struggle.
7.2 Maintenance & Support
Unlike a vendor offering support, you may be responsible for maintenance, updates, monitoring. This demands expertise.
7.3 Licensing and Compliance Risks
Even open source licences have obligations. Some models restrict commercial use or require attribution. Non-compliance can lead to legal risks.
7.4 Model Quality, Safety & Alignment
Open source models may lag proprietary counterparts in alignment, safety, moderation. They may also have undesirable biases if training data or fine-tuning is inadequate.
7.5 Versioning and Project Longevity
Some OSS projects may get abandoned, or have fewer updates. If you depend on a model whose community dies, you may be at risk.
7.6 Infrastructure Costs and Hidden Costs
While no license fees may exist, compute, energy, personnel, and monitoring costs exist. These must be anticipated.
8. How to Choose and Deploy the Right Open Source Large Language Model

8.1 Define Your Use-Case & Constraints
What is your target application? Chatbot, multilingual translation, code generation, summarisation? What resources (compute, budget) do you have? What languages/regions do you need?
8.2 Evaluate Model Performance & Community Health
Check metrics, benchmarks (MMLU, HumanEval, etc). See whether the project is active (recent commits, community support). For example, PolyLM claims improved multilingual performance. arXiv
8.3 Check Licence and Commercial Usage Terms
For production or business use, ensure the licence allows your intended usage. Some models may be “open” but restrict commercial deployment.
8.4 Infrastructure & Deployment Strategy
Will you deploy on-premises or cloud? Do you have GPUs/TPUs? Consider quantisation, model size (7B, 13B, 70B…), inference latency, context window size.
8.5 Fine-Tuning, Safety, Ethics
Plan for fine-tuning on your data, and put safety frameworks in place (moderation filters, monitoring). Ensure alignment with your brand/region values.
8.6 Monitoring, Maintenance & Version Upgrades
Establish processes for updating model weights, patching vulnerabilities, logging performance, monitoring drift.
8.7 Budgeting & ROI
Consider total cost (infrastructure + personnel + energy) vs benefits (productivity gain, custom service, cost avoidance).
9. Future Trends in Open Source Large Language Models

9.1 Growing Parameter & Context Size
As hardware improves, open source models are scaling to even higher parameter counts and larger context windows. For example multiple models now support 100K+ token contexts.
9.2 Multimodal and Domain-Specific Models
Open source LLMs are increasingly multimodal (text + vision + code + audio) and domain-specific (medicine, law, regional languages).
9.3 Smaller, Efficient Models
Not just large size: efficient models (7B-13B parameters) with clever architecture or retrieval-augmented setups enable local deployment on edge or low-cost hardware.
9.4 Ecosystem Tooling and Infrastructure
Better tooling (quantisation, inference servers, fine-tuning libraries) will make open source LLMs easier to adopt. Projects like h2oGPT signal this trend.
9.5 Ethical, Transparent & Auditable Models
Because open source is more transparent, governance, model auditing, bias mitigation will become more important—especially for enterprises and regulated industries.
9.6 Localisation & Regional Language Models
As open source grows, more focus will be on non-English models and regional languages—important for global and emerging markets.
10. Summary & Actionable Checklist
Summary
Open source large language models are reshaping how AI is built, deployed, and scaled. They offer transparency, customisation, cost control and innovation opportunities. But they also bring infrastructure demands, maintenance and licensing considerations. Choosing the right model, planning deployment, and managing risks are key.
Actionable Checklist
- Define your target use-case, language and domain needs for the LLM.
- Audit your infrastructure (GPU/TPU availability, budget).
- Research top open source LLMs (BLOOM, LLaMA, GPT-J, h2oGPT, etc) and their licences.
- Select a model size that fits your compute budget while meeting performance needs.
- Ensure licence compliance and commercial usage rights.
- Plan deployment: cloud vs on-premises, inference latency, quantisation.
- Prepare fine-tuning or instruction-tuning strategies on your data.
- Implement safety, moderation, monitoring frameworks.
- Document and train your team on usage, maintenance, updates.
- Monitor performance, cost, ROI, and plan for upgrade or model replacement.
11. Frequently Asked Questions (FAQs)
Q: Are open source large language models as good as proprietary ones?
It depends. Many open source LLMs achieve impressive performance, especially in research settings. However, proprietary models may still lead in alignment, scale or commercial support. The gap is narrowing rapidly. For example, IBM mentions open source models like MPT-30B outperforming GPT-3. IBM+1
Q: Can I use open source LLMs for commercial applications?
Yes—many models allow commercial use, but you need to verify the licence terms. Some models restrict commercial use, attribution or require open-source derivatives. Always review the licence carefully.
Q: Do I need massive GPUs to run them?
Larger models (70B+ parameters) often require multiple GPUs/TPUs. But many organisations use smaller efficient models (7B-13B) or quantised versions that reduce hardware demands. Retrieval-augmented setups also reduce compute.
Q: What about data privacy and security?
Running open source LLMs on-premises or in your private cloud gives you more control over data. You should ensure inference is secure, monitor model inputs/outputs, and guard against data leaks.
Q: How will open source LLMs evolve?
Expect more efficient models, multimodal capabilities, regional language support, better tools for fine-tuning and deployment, and more robust governance/ethics frameworks.

